大文件上传
大约 4 分钟
大文件上传
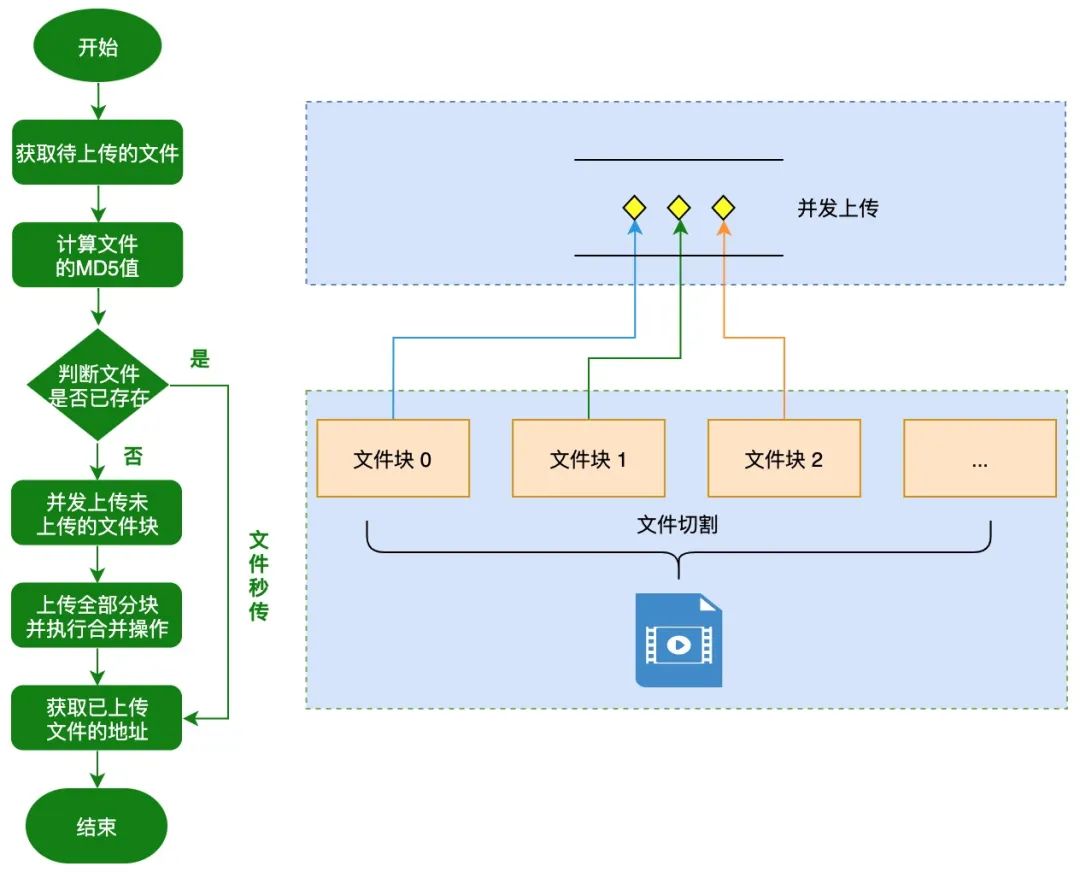
大文件上传处理流程
使用spark-md5获取上传文件的 MD5
function calcFileMD5(file, chunkSize = 1 * 1024 * 1024) {
// 2M
return new Promise((resolve, reject) => {
// let chunkSize = 2097152, // 2M
chunks = Math.ceil(file.size / chunkSize)
currentChunk = 0
spark = new SparkMD5.ArrayBuffer()
fileReader = new FileReader()
fileReader.onload = e => {
spark.append(e.target.result)
currentChunk++
if (currentChunk < chunks) {
loadNext()
} else {
resolve(spark.end())
}
}
fileReader.onerror = e => {
reject(fileReader.error)
reader.abort()
}
function loadNext() {
let start = currentChunk * chunkSize,
end = start + chunkSize >= file.size ? file.size : start + chunkSize
fileReader.readAsArrayBuffer(file.slice(start, end))
}
loadNext()
})
}
使用asyncPool函数控制请求并发
async function asyncPool(poolLimit, array, iteratorFn) {
const ret = [] // 存储所有的异步任务
const executing = [] // 存储正在执行的异步任务
for (const item of array) {
// 调用iteratorFn函数创建异步任务
const p = Promise.resolve().then(() => iteratorFn(item, array))
ret.push(p) // 保存新的异步任务
// 当poolLimit值小于或等于总任务个数时,进行并发控制
if (poolLimit <= array.length) {
// 当任务完成后,从正在执行的任务数组中移除已完成的任务
const e = p.then(() => executing.splice(executing.indexOf(e), 1))
executing.push(e) // 保存正在执行的异步任务
if (executing.length >= poolLimit) {
await Promise.race(executing) // 等待较快的任务执行完成
}
}
}
return Promise.all(ret)
}
文件切片上传
/**
* 校验文件是否上传过,分三种情况:
* 文件已存在 秒传
* 有部分切片 断点续传
* 无切片 切片上传
* */
checkFileFn(fileMd5,fileName) {
return new Promise(async (resolve, reject) => {
const res = await axios.get(`/file/check?fileMd5=${fileMd5}&fileName=${fileName}`)
resolve(res.data.data)
})
},
/**
* 上传切片文件
* 根据校验文件接口判断是否文件已上传
* */
async function uploadFile(e) {
if (!e.target.files.length) return;
const file = e.target.files[0] // 获取待上传的文件
const fileMd5 = await this.calcFileMD5(file); // 计算文件的MD5
const fileStatus = await this.checkFileFn(fileMd5,file.name) // 判断文件是否已存在
if (fileStatus.data && fileStatus.data.isExists) {
alert("文件已上传[秒传]");
return;
} else {
await this.upload({
file, // 文件对象
fileMd5, // 文件MD5值
fileSize: file.size, // 文件大小
chunkSize: 1 * 1024 * 1024, // 分块大小
chunkIds: fileStatus.data.chunkIds, // 已上传的分块列表
poolLimit: 3, // 限制的并发数
});
}
await axios.post(`/file/merge`,{'fileMd5':fileMd5,'fileName':fileName}) // 发起合并请求
}
function upload({ file, fileMd5, ileSize, chunkSize, chunkIds,poolLimit = 6}) {
const chunks = typeof chunkSize === "number" ? Math.ceil(fileSize / chunkSize) : 1;
return asyncPool(poolLimit, [...new Array(chunks).keys()], (i) => {
if (chunkIds.indexOf(i + "") !== -1) { // 已上传的分块直接跳过
return Promise.resolve();
}
let start = i * chunkSize;
let end = i + 1 == chunks ? fileSize : (i + 1) * chunkSize;
const chunk = file.slice(start, end); // 对文件进行切割
return uploadChunk({
chunk,
chunkIndex: i,
fileMd5,
fileName: file.name,
});
});
}
/**
* 切片信息封装为formdata
*
*/
function uploadChunk({chunk, chunkIndex, fileMd5, fileName }) {
let formData = new FormData();
formData.append("file", chunk); // 使用FormData可以将blob文件转成二进制binary
formData.append("chunkIndex", chunkIndex);
formData.append("fileName", fileName);
formData.append("fileMd5", fileMd5);
return axios.post(`/file/upload`,formData)
}
node 服务
var express = require('express')
var router = express.Router()
const multiparty = require('multiparty') // 中间件,处理FormData对象的中间件
const path = require('path')
const fse = require('fs-extra') //文件处理模块
const UPLOAD_DIR = path.resolve(__dirname, '..', 'largeFilesChunks')
const MERGE_DIR = path.resolve(__dirname, '..', 'largeFiles')
let haveMergedFileMd5List = ['']
router.get('/', function (req, res) {
res.json({ status: 200, message: '' })
})
router.post('/upload', function (req, res) {
console.log(req)
const multipart = new multiparty.Form() // 解析FormData对象
multipart.parse(req, async (err, fields, files) => {
if (err) {
//解析失败
console.log(err)
throw err
}
console.log('fields=', fields)
console.log('files=', files)
const [file] = files.file
const [fileName] = fields.fileName
const [chunkIndex] = fields.chunkIndex
const [fileMd5] = fields.fileMd5
const filePath = `${UPLOAD_DIR}/${fileMd5}`
console.log(fileName)
if (!fse.existsSync(filePath)) {
//文件夹不存在,新建该文件夹
await fse.mkdirs(filePath)
console.log(22)
}
await fse.move(file.path, `${filePath}/${chunkIndex}`)
// res.json({status: 200, message: `上传成功`});
res.json({ status: 200, message: `${chunkIndex}上传成功` })
})
})
router.get('/check', async function (req, res) {
console.log('/check', req.query)
const { fileMd5, fileName } = req.query
console.log(fileMd5)
let status = ''
let chunkList = []
const filePath = `${UPLOAD_DIR}/${fileMd5}`
fse.readdir(MERGE_DIR, (err, files) => {
if (err) throw err
if (files.includes(fileName)) {
status = 1 //已存在 秒传
res.json({ status: 200, data: { isExists: true, chunkList: chunkList } })
} else if (fse.existsSync(filePath)) {
status = 2 // 断点续传
fse.readdir(filePath, (err, files) => {
if (err) throw err
console.log('chunks', files)
chunkList = files
res.json({ status: 200, data: { isExists: false, chunkIds: chunkList } })
})
} else {
status = 0 //没上传过 切片
res.json({ status: 200, data: { isExists: false, chunkIds: chunkList } })
}
})
})
router.post('/merge', async (req, res) => {
console.log(req)
const fileMd5 = req.body.fileMd5
const fileName = req.body.fileName
const chunkSize = 1 * 1024 * 1024
const mergeFilePath = path.resolve(MERGE_DIR, fileName) //合并文件路径
const chunkDirPath = path.resolve(UPLOAD_DIR, fileMd5)
let chunkPaths = await fse.readdir(chunkDirPath) //读取切片路径
chunkPaths.sort((a, b) => a - b) //切片排序
const pipeStream = (path, writeStream) => {
return new Promise(resolve => {
// 创建可读流,读取所有切片
const readStream = fse.createReadStream(path)
readStream.on('end', () => {
// fse.unlinkSync(path)// 读取完毕后,删除已经读取过的切片路径
resolve()
})
readStream.pipe(writeStream) //将可读流流入可写流
})
}
const arr = chunkPaths.map((chunkPath, index) => {
return pipeStream(
path.resolve(chunkDirPath, chunkPath),
// 在指定的位置创建可写流
fse.createWriteStream(mergeFilePath, {
start: index * chunkSize,
end: (index + 1) * chunkSize,
})
)
})
await Promise.all(arr).then(_ => {
//保证所有的切片都被读取
res.json({
status: 200,
data: {
code: 1,
},
})
})
})
module.exports = router
优化点
web-worker 计算 md5
当文件较大时,可启用 web-worker 处理计算 MD5,减少异步计算时间
ajax 请求控制并发
由于浏览器请求数量有限制,当切片文件较大时,可使用队列方式实现控制同时请求的数量
断点续传 切片上传 秒传